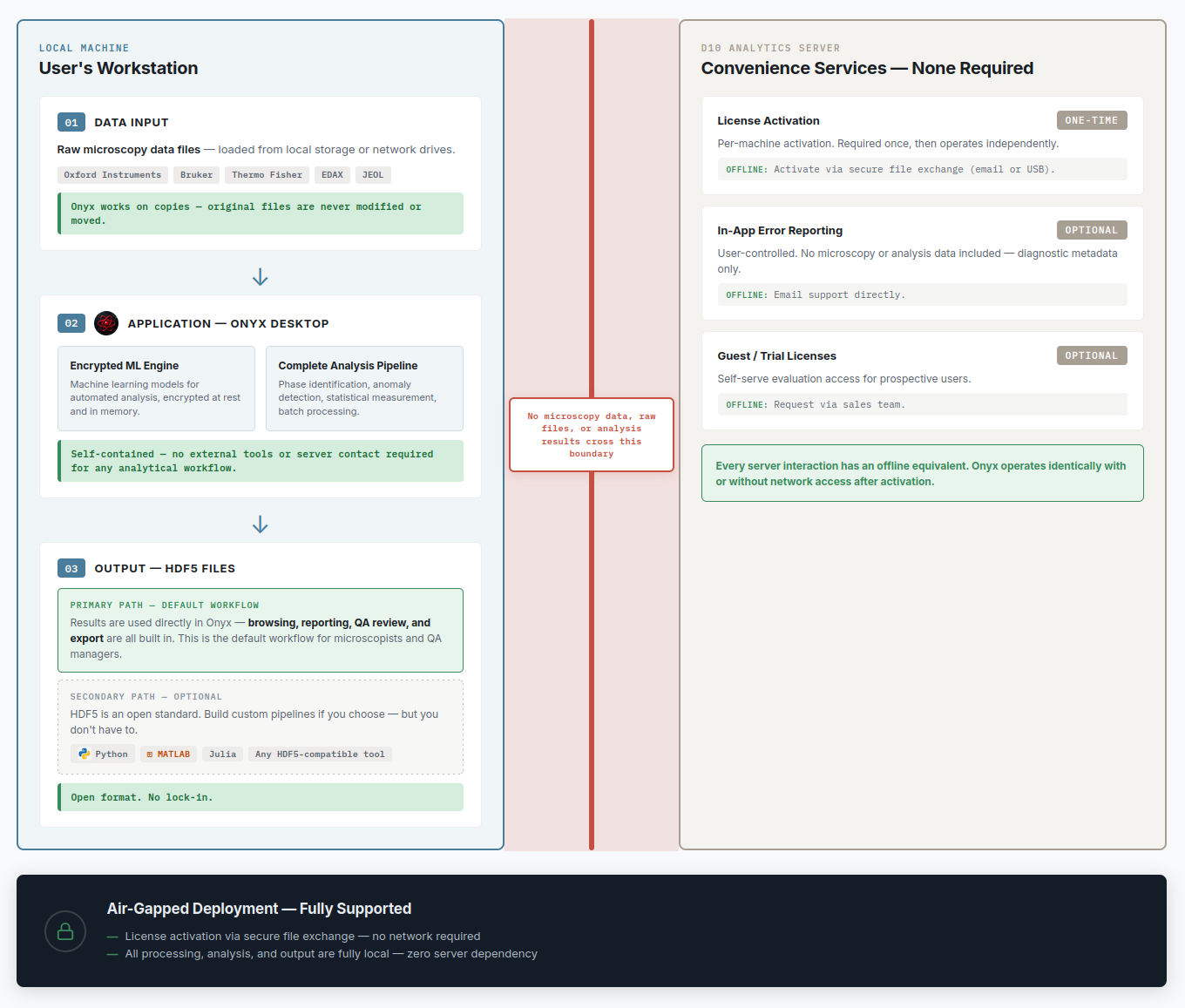
Security & Data Architecture
Completely Offline Data Processing — Zero IP Risk
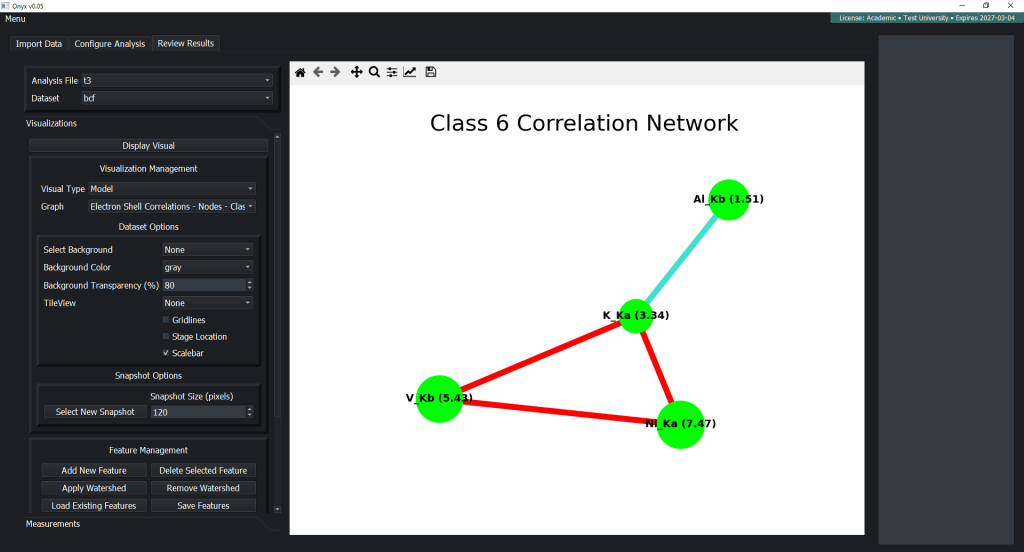
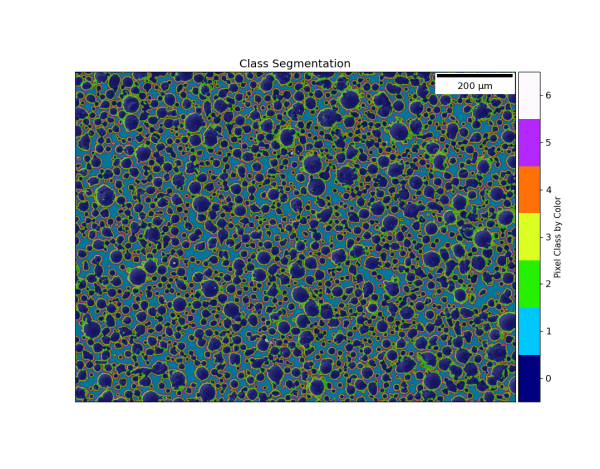
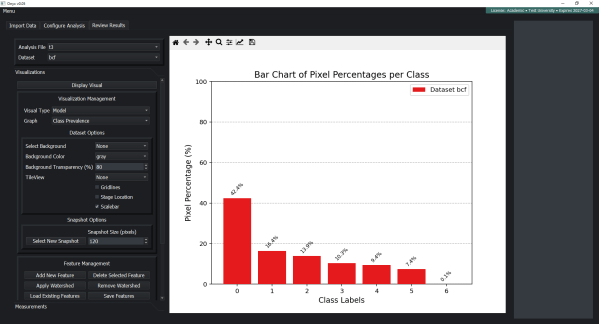
Open-Standard Output (HDF5)
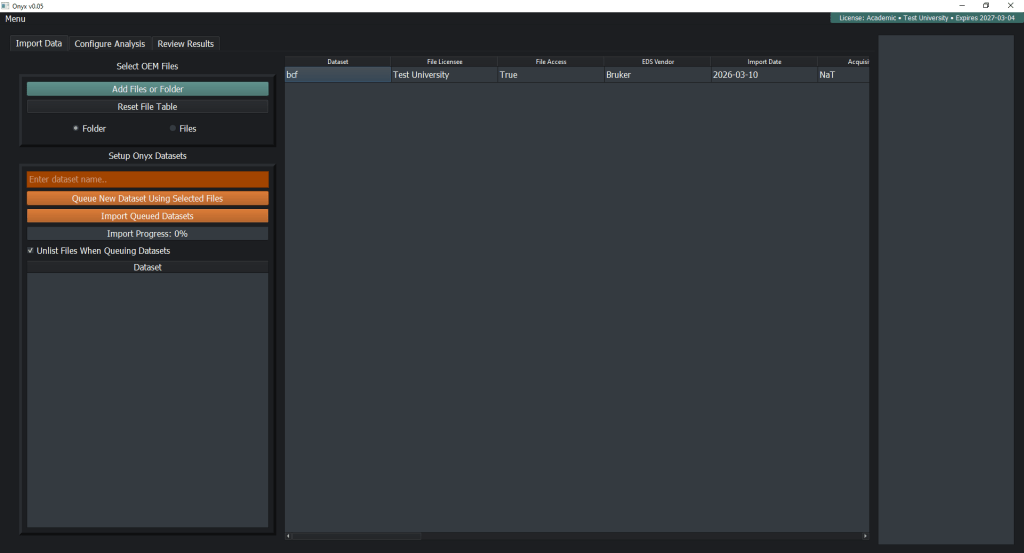
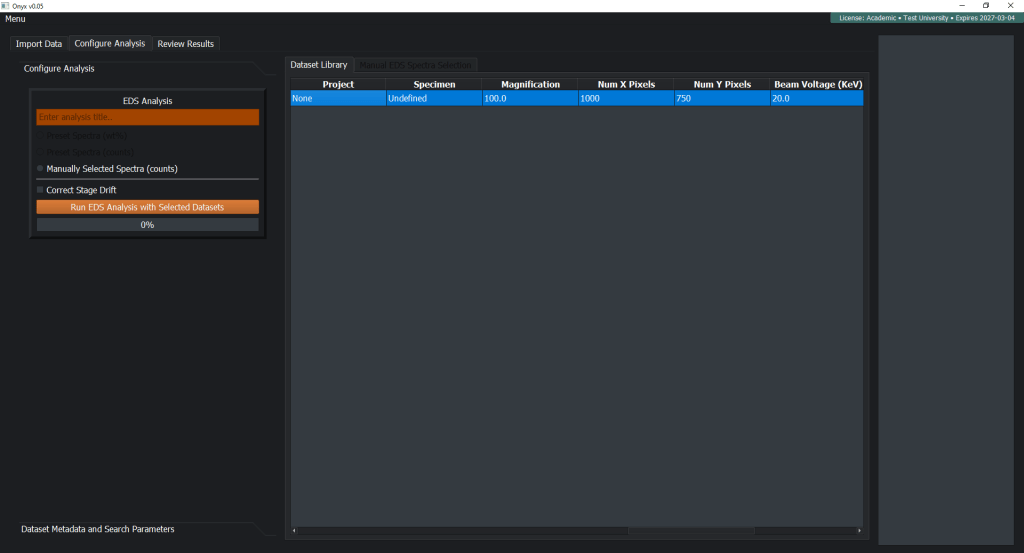
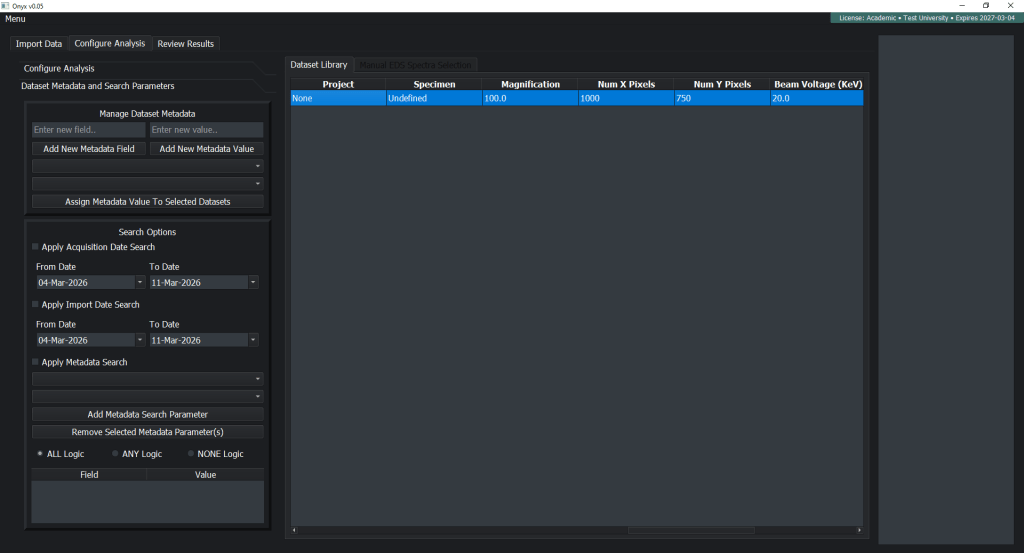
Onyx processes all microscopy data locally — your raw files, analysis results, and metadata never leave your machine. The only network activity is license verification and optional, user-controlled error reporting. No microscopy or analysis data is transmitted. For organizations where intellectual property security is non-negotiable — defense, aerospace, semiconductor, nuclear — this architecture eliminates cloud-related IP risk entirely. Air-gap deployments are supported by default. Onyx works exclusively on copies of your raw data; original files are never modified.
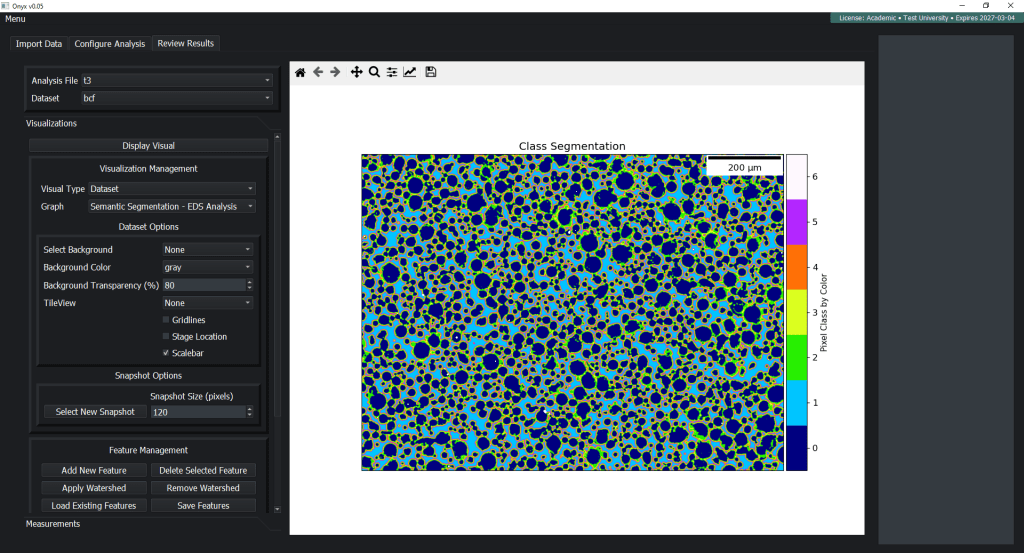
Every analysis result is stored in HDF5. No proprietary format lock-in. Read your results with Python, MATLAB, Julia, or any HDF5-compatible tool. The proprietary component is the ML engine (encrypted); the analysis it produces belongs to you.